This is a response to this blog post
The GH engineers correctly identify the MySQL dependency as a problem. It’s such an easy one to remove, though!
The MySQL database is serving as a simple map of URLs to fileservers. We can do that with cryptography instead.
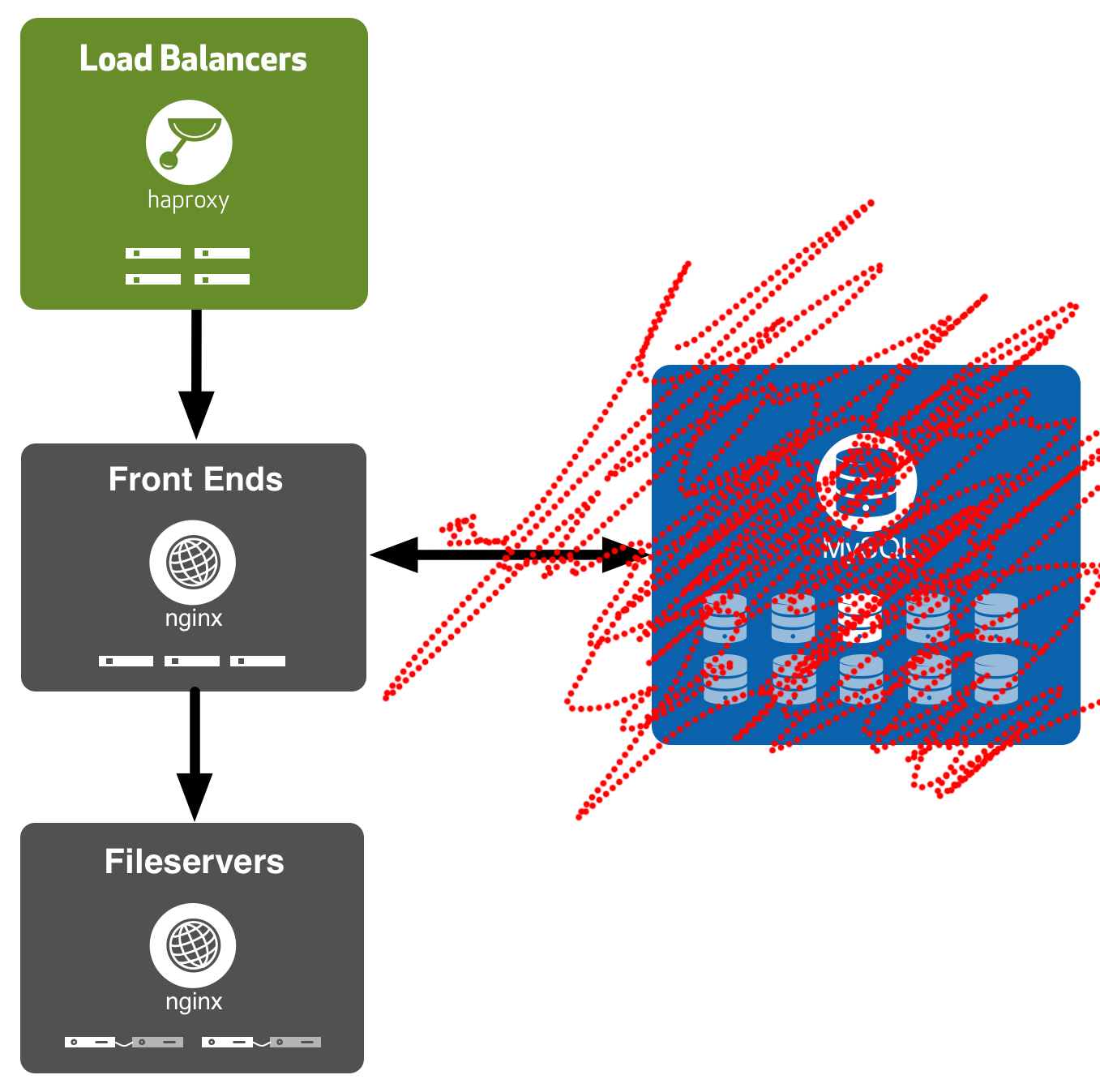
In that Lua call, instead of doing a database query, take an md5sum of the request. Compare the result to a static table you hardcode into your script. That table splits up the entire possible range of MD5 hashes into n buckets. It looks something like:
1a..1c
bucket1
1d..1f
bucket2
etc...
Every time you get a request for a given URL it will hash exactly the same way and be routed to exactly the same bucket.
The Lua function returns that bucket. nginx then proxy_passes the request to a given upstream. Those upstreams are all statically defined in the nginx config file like:
bucket1:
fileserver1.internalDNS.github.com
fileserver2.internalDNS.github.com
bucket2:
fileserver3.internalDNS.github.com
fileserver4.internalDNS.github.com
You can have as many fileservers as you like in each bucket depending on how much redundancy you want. Nginx will balance traffic between them based on one of a few possible methods. You can configure it however you like.
Every time a request for a URL is made it hashes exactly the same way and goes to exactly the same place. You can make changes to your infrastructure by pointing your DNS at different places.
The number of buckets to choose is up to you. You want something large enough that it will accommodate future demand (must be greater than the total number of fileservers you will need to store your assets) but small enough that it’s not a pain in the bum to work with. 100 is probably as good a number as any.
The other side of the coin is the Jekyll workers. Presumably in this system there are servers whose job it is to render the markdown into static HTML when you git push. All they need to do is implement the same algorithm with the same table. That way they always know which set of fileservers they should be persisting their assets to. Neat!
Yay for less moving parts.